Method
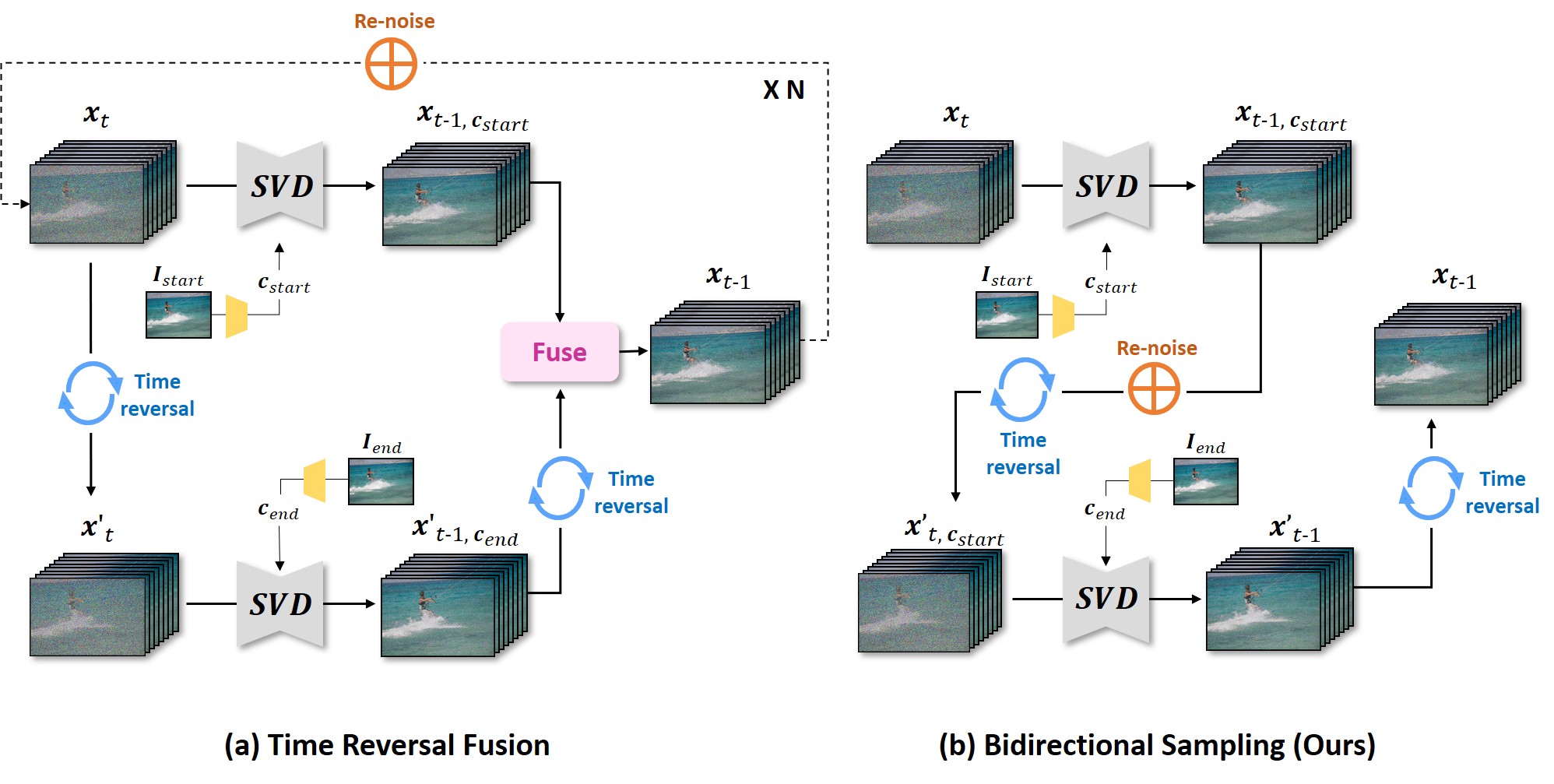
Comparison of denoising processes between (a) Time Reversal Fusion method and (b) bidirectional sampling (Ours).
Our key innovation lies in the sequential sampling of the temporal forward path and the temporal backward path by integrating a single re-noising step between them.
On-manifold sampling
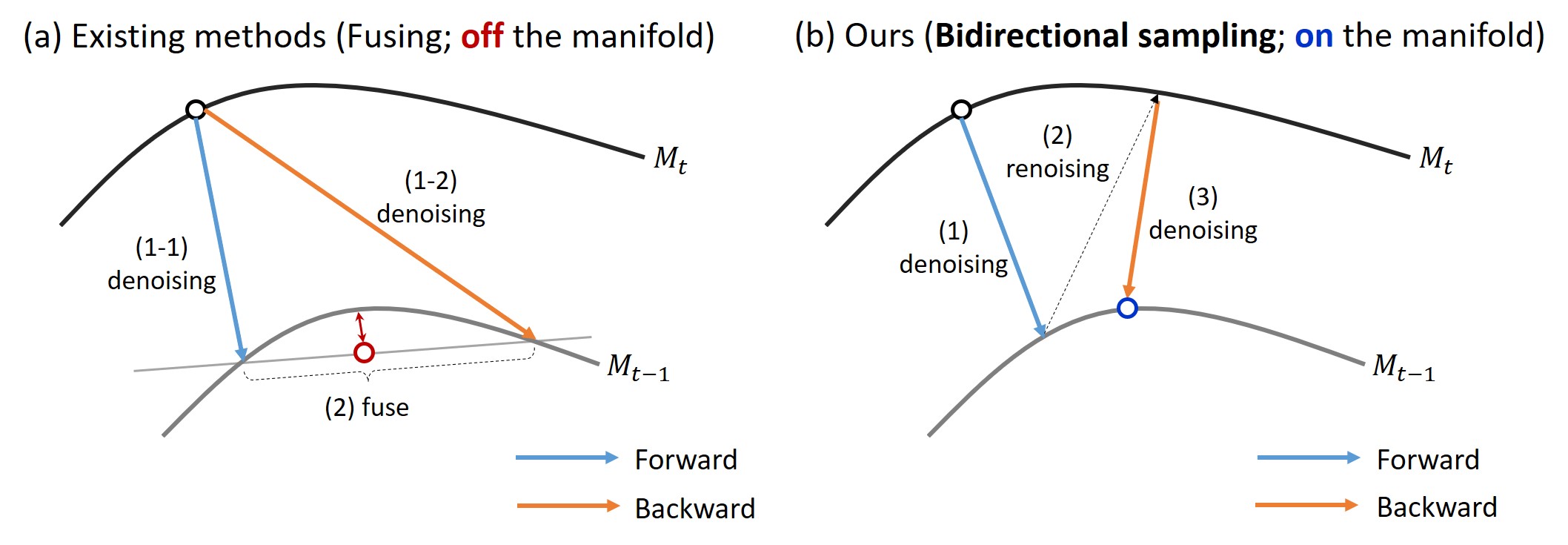
In the geometric view of diffusion models, the sampling process is typically described as iterative transitions moving from the noisy manifold to the clean manifold.
From this perspective, (a) fusing two intermediate sample points through linear interpolation on a noisy manifold can lead to an undesirable off-manifold issue,
where the generated samples deviate from the learned data distribution.
(b) Bidirectional sampling effectively addresses this issue by sequentially sampling both the temporal forward and backward paths, with a single re-noising step in between.
This approach enables on-manifold sampling, ensuring that the generated samples stay close to the learned data distribution.











